Having had some success with batch normalization for a convolutional net I wondered how that’d go for a recurrent one and this paper by Cooijmans et al. got me really excited. I decided to try and reimplement the results from their paper on the sequential mnist task.
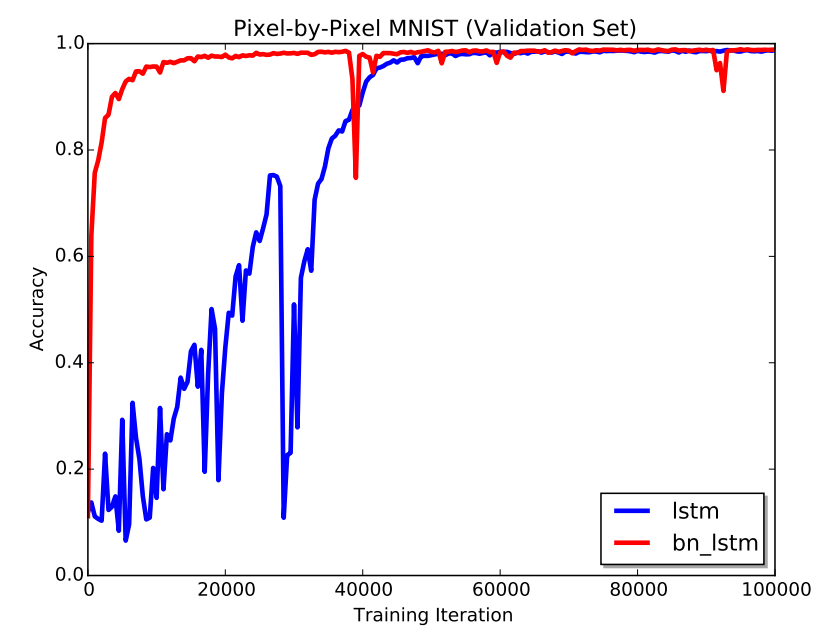
Sequential mnist was more involved than I first thought as it actually required decent running times on my not too awesome 2GB GTX 960 GPU. Finally, after having implemented almost every single detail of the paper, the results came out okay.
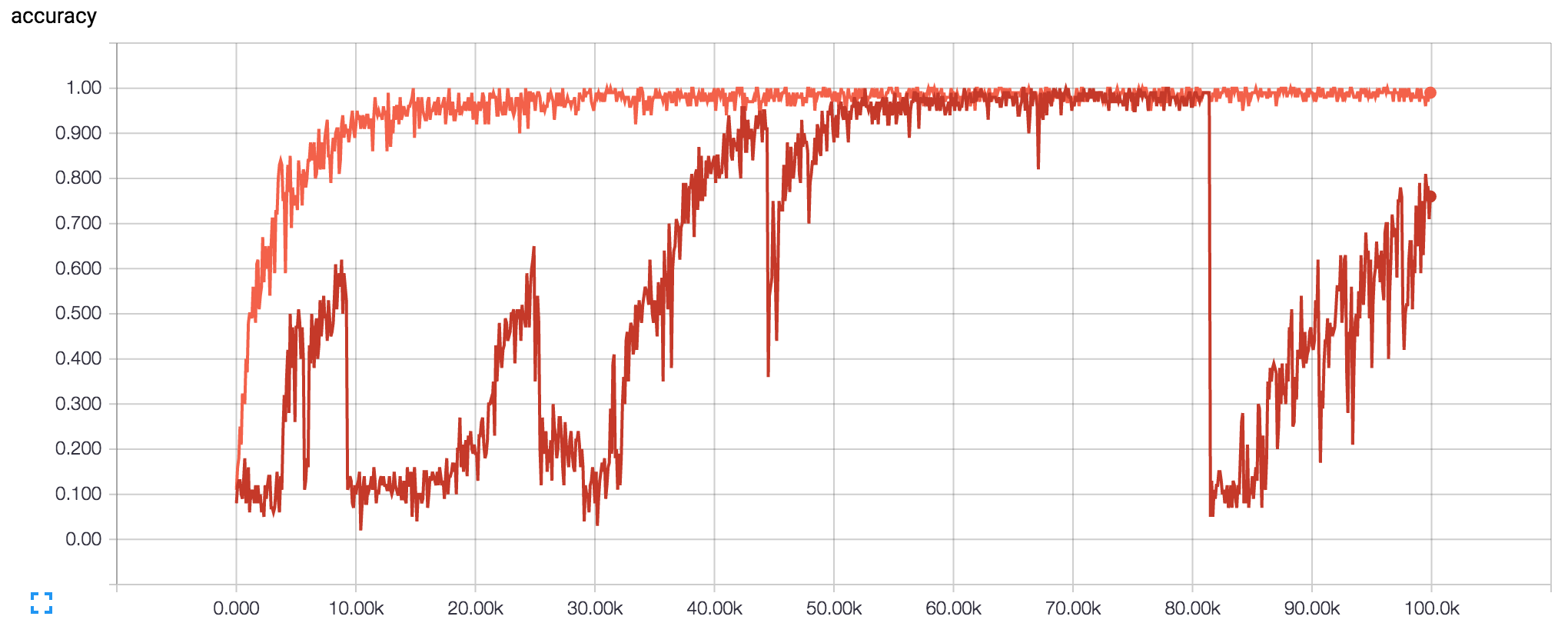
They seem very similar, except for my vanilla LSTM totally falling off the rails and is in the middle of trying to recover towards the end. Luckily the batch normalized LSTM works as reported. Yay!
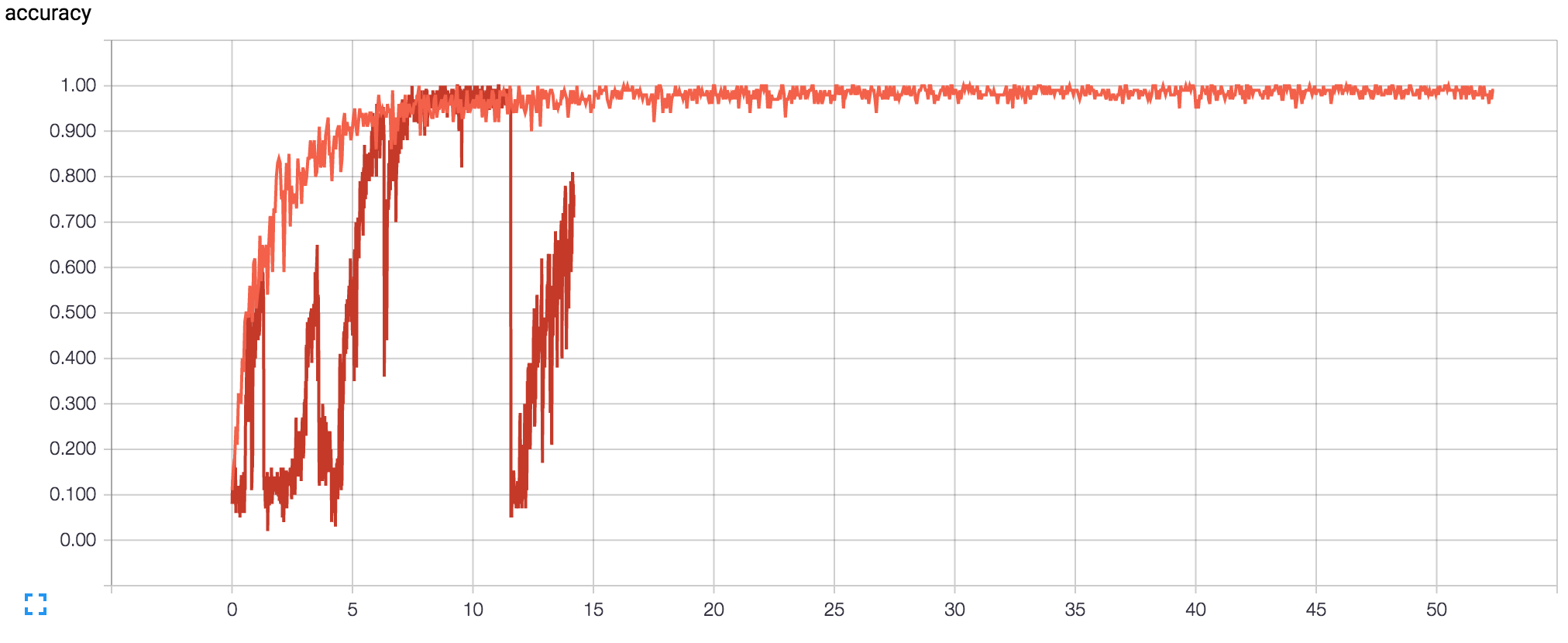
A more interesting plot is the two runs plotted against wall time instead of step time. The step times for the batch normalized version was 4 times the vanilla one, and in reality converged just as slow as the vanilla LSTM. It could be something crazy bad in my code, but for the sequential mnist the recurrent network is unrolled to 784 steps and calculating the mean and variance statistics for each of those steps is probably heavy.
The code is on github, and is the only implementation of batch normalized LSTM for Tensorflow I’ve seen. If you see any performance error I might’ve done, I’d love to know!